
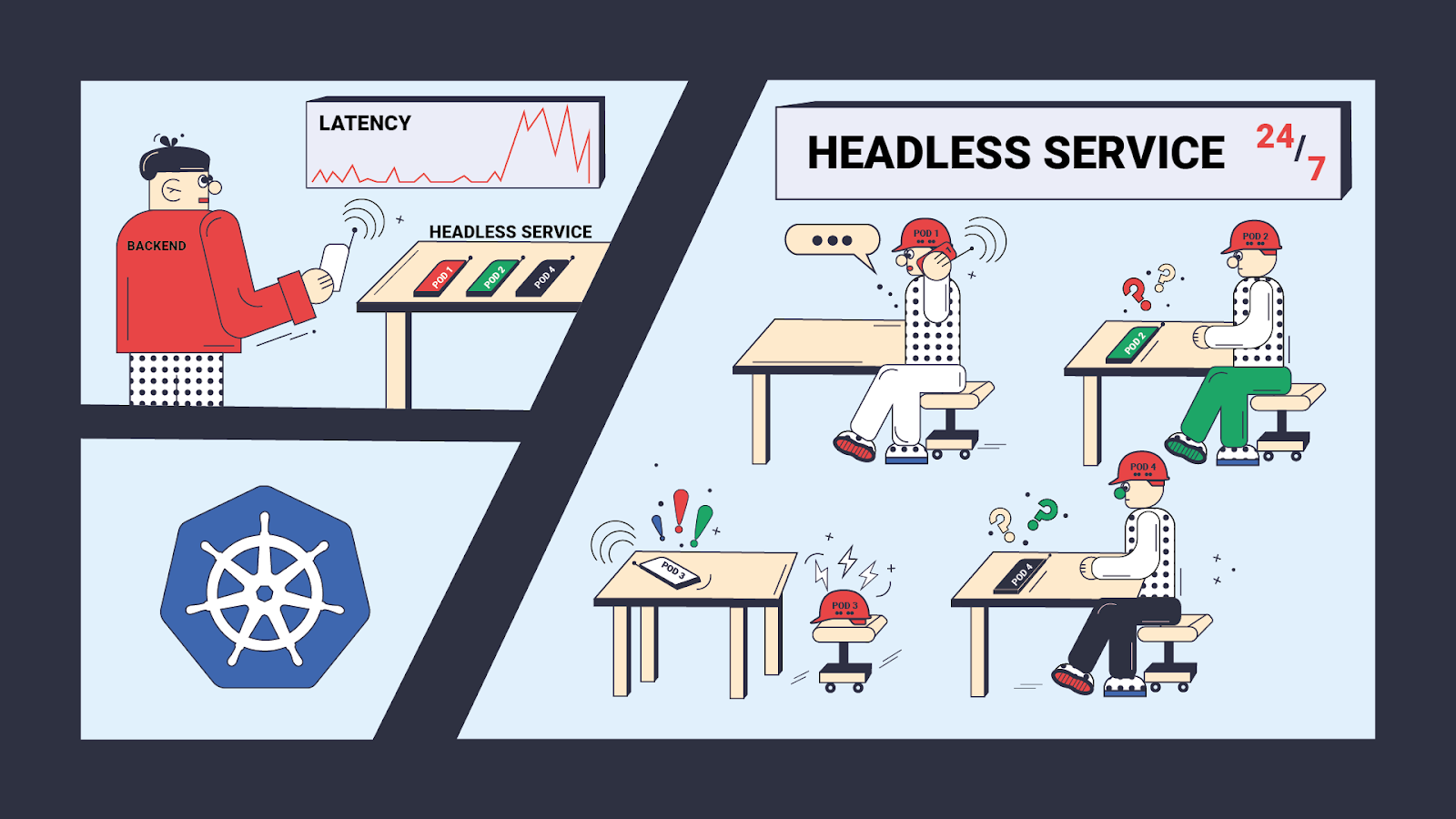
 Мы столкнулись с достаточно занятным поведением при работе с Headless-сервисом в Kubernetes. В нашем случае проблема
возникла с mongos, но она актуальна для любого Headless-сервиса.
Мы столкнулись с достаточно занятным поведением при работе с Headless-сервисом в Kubernetes. В нашем случае проблема
возникла с mongos, но она актуальна для любого Headless-сервиса.
Приглашаю вас почитать нашу историю и самим попробовать поиграться с этой проблемой локально.
На одном из проектов мы используем MongoDB и Kubernetes. У MongoDB есть компонент: mongos. Через него выполняются запросы в шардированном MongoDB кластере (можно считать, что это просто хитрый proxy). До переезда в Kubernetes сервисы mongos устанавливались непосредственно на каждый хост.
При переезде сервисов в Kubernetes мы поселили пул mongos в Headless-сервис с автоматическим масштабированием Deployment через HPA (Horizontal Pod Autoscaler).
Через некоторое время выяснилось, что приложению при уменьшении количества Pod с mongos становится не очень хорошо.
Путем отладки выяснилось, что приложение подвисает именно при попытке установить подключение с mongos (net.Dial в
терминах Go) и по времени совпадает с остановкой какого-либо Pod.
Для начала надо уточнить, что такое Headless-сервис: это сервис, который не использует отдельный IP-адрес для
маршрутизации запросов (ClusterIP: None). В этом случае под DNS именем сервиса видны IP всех Pod, которые в этот
сервис входят.
Headless-сервисы полезны, когда приложение само должно управлять тем, к какому Pod подключаться, например:
- mongodb-клиент использует IP сервера, с которым он работает для того, чтобы запросы для одного курсора шли на один
хост (курсор «живёт» на mongos). В случае использования
ClusterIPмогут «теряться» курсоры даже для коротких запросов. - gRPC клиенты держат по одному соединению с сервисами и сами управляют запросами, мультиплексируя запросы к одному
серверу. В случае использования
ClusterIPклиент может создать одно подключение и нагружать ровно один Pod сервера.
Так как клиент сам управляет, к каким Pod он подключается, возможна ситуация, когда клиент помнит IP-адрес уже удалённого Pod. Причины этого просты:
- список Pod передаётся через DNS, а DNS кэшируется;
- клиент сам по себе кэширует ответы от DNS и список сервисов.
Что же происходит в случае, если клиент пытается подключиться к уже несуществующему Pod?
А в этом случае запросы уходят уже на немаршрутизируемый хост и на них никто не отвечает. Так как ответа нет, клиент начинает слать повторные запросы на подключение пока не пробьёт таймаут.
При этом, в случае если Pod еще не поднялся или был отстрелен по Out of Memory, но еще не был удалён, то при попытке подключиться клиент получает ошибку “connection refused” практически сразу. И это гораздо более гуманное решение, чем ждать у моря погоды пока не пробьём таймаут.
Когда стала понятна причина, решить проблему было делом техники:
- Мы добавили ожидание сигнала
SIGTERMв Pod-е с mongos-ом. При получении этого сигнала мы продолжали работать еще 45 секунд до времени инвалидации DNS (чтобы адреса новых Pod-ов доехали до клиента). После этой паузы завершали mongos и делали еще одну паузу в 15 секунд (чтобы переподключение по старому IP отшивалось по ошибке “connection refused”, а не таймауту). - Мы выставили
terminationGracePeriodSecondsв две минуты, чтобы Pod принудительно не отстрелили до его завершения.
Небольшая ремарка по поводу minReadySeconds
Проблема с остановкой Pod наиболее ярко проявляет себя при перевыкатке сервисов.
Изначально первопричиной казалось то, что выкатка успевает завершиться быстрее, чем обновляются кэши IP-адресов сервиса в клиентском приложении (клиент пытается идти на старые Pod которых нет, а про новые он еще не знает).
Для исправления мы просто замедлили выкатку с помощью параметра minReadySeconds. Это сделало проблему менее острой, но
не решило её: остались таймауты при подключении к IP для уже не существующего Pod.
Тем не менее параметр minReadySeconds полезен из-за того, что выкатка не ждёт завершения удаления Pod после перехода
его в состояние Terminating. В результате при раскатке сервиса мы можем на время добавленных пауз получить x2 Pod.
К тому же, если на клиенте не возникает нежелательных эффектов от недоступности части IP-адресов сервиса, то задержку
для инвалидации DNS можно переместить в minReadySeconds.
Примером, для которого достаточно только minReadySeconds являются gRPC-сервисы: там клиент держит по одному
подключению к каждому серверу и раскидывает запросы между уже имеющимся подключениями, а не подключается к сервису при
создании клиентской сессии.
Как поиграться с этой проблемой локально?
Эту ситуацию можно легко воспроизвести в MiniKube на примере nginx.
Для этого надо понадобится headless Service:
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
clusterIP: None
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
И тестовая утилита:
package main
import (
"fmt"
"net"
"os"
"time"
)
const timeFormat = "15:04:05.999"
func main() {
address := os.Args[1]
last := ""
ticker := time.NewTicker(time.Millisecond * 100)
t := time.Now()
fmt.Printf("%s: === %s\n", t.Format(timeFormat), address)
for {
conn, err := net.DialTimeout("tcp", address, time.Millisecond*100)
var msg string
if conn != nil {
msg = fmt.Sprintf("connected (%s)", conn.RemoteAddr())
_ = conn.Close()
}
if err != nil {
msg = err.Error()
}
if last != msg {
now := time.Now()
if last != "" {
fmt.Printf("%s: --- %s: %v\n", now.Format(timeFormat), last, now.Sub(t))
}
last = msg
fmt.Printf("%s: +++ %s\n", now.Format(timeFormat), last)
t = now
}
<-ticker.C
}
}
Запустим тестовую утилиту для подключения к сервису nginx по 80-му порту. Она будет выводить результат попытки
подключиться к сервису (пока не успешный, так как сервис смотрит в никуда):
#!/bin/bash
echo "
tee dialer.go << EEOF
$(cat dialer.go)
EEOF
go run dialer.go nginx:80
" | kubectl --context=minikube run -i --rm "debug-$(date +'%s')" --image=golang:1.16 --restart=Never --
Вывести она должна что-то вида:
16:57:19.986: === nginx:80
16:57:19.988: +++ dial tcp: lookup nginx on 10.96.0.10:53: server misbehaving
Пока оставим окно с утилитой и потом будем в него посматривать.
Простой Deployment без задержек
Добавим в сервис Deployment:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Параметр replicas для эксперимента равен единице, чтобы не скакать между IP-адресами.
На боевом Deployment должны быть так же livenessProbe и readinessProbe. Но в данном эксперименте они будут только
мешать.
И сделаем «обновление» Deployment:
#!/bin/bash
kubectl --context minikube rollout restart deployment/nginx
От этой команды произойдёт перевыкатка Deployment. При этом важно отметить, что схема выкатки по умолчанию: поднять новый Pod и только затем погасить старый Pod. То есть всегда будет запущен как минимум один Pod.
В выводе тестовой утилиты мы увидим примерно следующее (комментарии добавлены отдельно):
# Здесь мы подключились к созданному Deployment и до обновления попытки
# подключения были успешны
17:04:08.288: +++ connected (172.17.0.10:80)
17:07:32.187: --- connected (172.17.0.10:80): 3m23.899438044s
# Здесь завершился nginx при остановке Pod, но клиент еще идет по старому
# кэшированному IP.
# Так как Pod существует, мы быстро получаем ошибку "connection refused"
17:07:32.187: +++ dial tcp 172.17.0.10:80: connect: connection refused
17:07:32.488: --- dial tcp 172.17.0.10:80: connect: connection refused: 301.155902ms
# Старый Pod уже удалён, но клиент всё еще идет по старому кэшированному IP.
# Так как по IP-адресу уже никто не отвечает, мы пробиваем таймаут.
17:07:32.488: +++ dial tcp 172.17.0.10:80: i/o timeout
17:07:38.448: --- dial tcp 172.17.0.10:80: i/o timeout: 5.960150161s
# Старый IP покинул кэш и мы подключились к новому Pod.
17:07:38.448: +++ connected (172.17.0.7:80)
Добавляем задержку перед удалением Pod.
Добавим в Deployment паузу после завершения сервиса, чтобы вместо долгого таймаута получать быстрый “connection
refused”:
#!/bin/bash
kubectl --context minikube patch deployment nginx --output yaml --patch '
---
spec:
template:
spec:
containers:
- name: nginx
command: [ "sh" ]
# Добавляем паузу после завершения nginx
args:
- "-c"
- "nginx -g \"daemon off;\" && sleep 60"
# К сожалению, sh не пробрасывает SIGTERM в дочерний процесс
lifecycle:
preStop:
exec:
command: ["sh", "-c", "nginx -s stop"]
# Увеличиваем время, которое отводится на остановку Pod-а перед
# его безусловным завершением
terminationGracePeriodSeconds: 180
'
Эта пауза нужна только при корректном завершении Pod (в этом случае процесс получает SIGTERM). Если процесс
завершается, к примеру, по Out Of Memory или Segmentation fault, то её быть не должно.
И еще раз сделаем «обновление» Deployment:
#!/bin/bash
kubectl --context minikube rollout restart deployment/nginx
В выводе тестовой утилиты мы увидим примерно следующее (комментарии добавлены отдельно):
# Здесь мы подключились к созданному Deployment и до обновления попытки
# подключения были успешны
17:58:10.389: +++ connected (172.17.0.7:80)
18:00:53.687: --- connected (172.17.0.7:80): 2m43.29763747s
# Здесь завершился nginx при остановке Pod, но клиент еще идет по старому
# кэшированному IP.
# Так как Pod существует, мы быстро получаем ошибку "connection refused".
# Существовать Pod будет до тех пор пока не завершится sleep после nginx.
18:00:53.687: +++ dial tcp 172.17.0.7:80: connect: connection refused
18:01:10.491: --- dial tcp 172.17.0.7:80: connect: connection refused: 16.804114254s
# Старый IP покинул кэш и мы подключились к новому Pod-у.
18:01:10.491: +++ connected (172.17.0.10:80)
Добавляем задержку перед остановкой Pod.
Добавим в Deployment паузу перед завершением сервиса, чтобы сервис отвечал, пока адрес Pod не покинет кэш на клиенте:
#!/bin/bash
kubectl --context minikube patch deployment nginx --output yaml --patch '
---
spec:
template:
spec:
containers:
- name: nginx
# Добавляем задержку перед остановкой nginx
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 60 && nginx -s stop"]
# Увеличиваем время, которое отводится на остановку Pod перед
# его безусловным завершением
terminationGracePeriodSeconds: 180
'
И еще раз сделаем «обновление» Deployment:
#!/bin/bash
kubectl --context minikube rollout restart deployment/nginx
В выводе тестовой утилиты мы увидим примерно следующее (комментарии добавлены отдельно):
# Здесь мы подключились к созданному Deployment и до обновления попытки
# подключения были успешны
18:05:10.589: +++ connected (172.17.0.7:80)
18:07:10.689: --- connected (172.17.0.7:80): 2m0.099149168s
# Старый IP покинул кэш и мы подключились к новому Pod.
# Старый Pod еще отвечает и из-за этого переключение прошло гладко.
18:07:10.689: +++ connected (172.17.0.10:80)
Какие нужны задержки?
Итого, для гладкого переключения необходимо две задержки.
-
Между
SIGTERMи остановкой приложения — чтобы на момент отключения клиента он не мог получить из DNS-кэша ровно тот же Pod и пойти на него.Эта задержка должна быть не меньше, чем время жизни записи в DNS-кэше.
Делать эту паузу больше, чем сумма времени жизни записи в DNS-кэше и времени жизни записи в кэше приложения не имеет особого смысла.
Если на клиенте не возникает нежелательных эффектов от недоступности части IP-адресов сервиса, то вместо паузы после
SIGTERMможно использоватьminReadySeconds. -
Между остановкой приложения и завершением Pod, чтобы при попытке клиента подключиться/переподключиться к этому Pod мы получали быстрый “connection refused”, а не ждали всё время таймаута.
Эта задержка должна быть подобрана так, чтобы с момента получения
SIGTERMи до завершения Pod прошло время не меньше суммы времени жизни записи в DNS кэше и времени жизни записи в кэше приложения.Теоретически, без неё можно было бы вообще обойтись, но некоторые клиенты могут начать активность по поиску новых адресов только после потери соединения клиента с приложением.
Конкретные длительности задержек надо подбирать индивидуально.